In this post I am going to explain about Oikoitea, my Final Project Degree to get my title of Computer Science Engineer at Universidad Nacional de Itapua.
It is an visual agenda built in Django that using Word Embeddings for Image Retrieval.
Augmentative and Alternative Systems are used to communicate with people with Autism. These are kinds of expression that try to replace the verbal language, and includes various systems of symbols: both graphics (photographs, drawings, pictograms, words or letters) and gestures (mimicry) , gestures or manual signs).
So, let’s start!
![]()
Etimology
First to all, what does Oikoitea mean? It derivates from two words
- Oikoite: a word in Guarani that means Everything is OK
- TEA: Acronym in Spanish of Transtorno del Espectro Autista or Austism Spectrum Disorder.
So… What is Oikoitea?
Oikoitea is a project that consists in the development of an Visual Agenda Manager, which is basically a sequences of activities that are represented with images, that aims to professionals to communicate with people with Autism Spectrum Disorder (TEA in Spanish).
There are applications that allow the dynamic management of visual agendas, but these applications allow you to search the images manually from the device, or by means of predefined text labels that are associated with the image.
In view that currently there are applications like this, it has been proposed the image retrieval by text using Natural Language Processing or NLP considering its respective descriptions attached to the images, looking for improvement in the retrieval taking into acount the semantic variations of the words.
What is the advantage of this? or What are we looking for doing this?
So basicly, it looks for a semantic searcher that considers not only the String comparison, rather a
NLP and Word Embeddings
It has been considered a technique of word representation called Word Embeddings that generates a Vector Space Model. During the information retrieval, the search term entered and the descriptions stored in the database have been vectorized based on the vocabulary of the VSM, for later comparison according to the cosine similarity metric and returning the results in an order of relevance.
Once the search has been achieved, it has been integrated together with a web application allowing the Management of Visual Agendas. Based on the results obtained, it has been demonstrated that with the proposed application, better results are obtained with respect to semantics than searches based on text labels.
Architecture
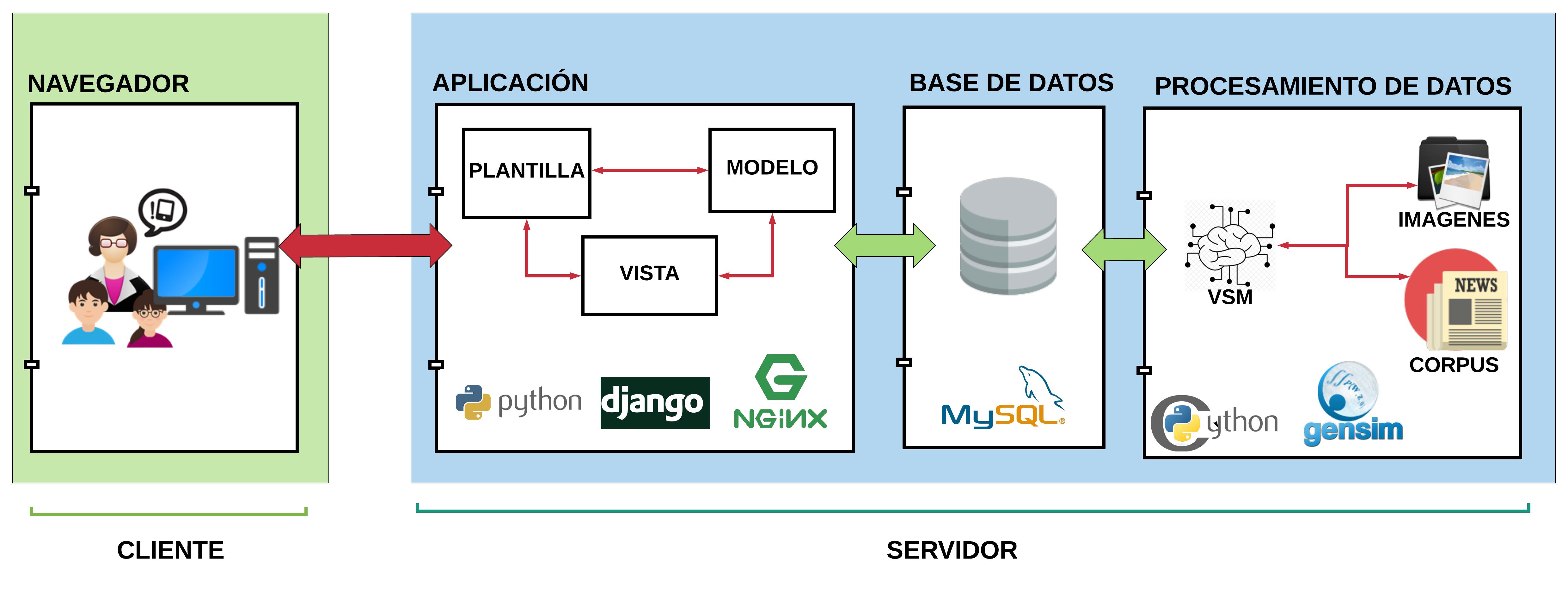
In the Picture 2, it has been chosen a client-server architecture as follow:
- in the -client side- the users are able to access to the aplication through a browser.
- in the -server side- there are the application with the MVT model, database and external process that does not interact with the users, but are essentials to the correct operation of the proposed application, such as:
- Image load to database
- translate process
- data cleaning
- training and re-training algorithms
- word to vector conversions
It can be note there’s a programming environment in the Picture 2
- Programming Language: Python 2.7.5
- Development Framework: Django 1.8
- Front End:
- HTML5
- CSS3
- Jquery.
- Database: MySQL 14.14
- Libraries for Natural Language Processing (PLN) and Word Embeddings:
- Gensim: set of Python libraries that contain Word2vec implementations used for Word Embeddings.
- Annoy: is responsible for searching for points in space that are close to a given reference point. It contains * implementations of Euclidean Distance, Manhatan, Cosine and Hamming.
Building a Semantic Information Retrieval
Ok, the idea is to build a searcher that measures semanticly
Before I start, In this article I am going to avoid details word embeddings algorithms, such as the Skip-gram or CBOW model But It could be considered for a future post. If you want to deepen about word embeddings essentials or NPL, I goint to recomend some materials that was useful to me to understand this content.
- Fuente 1
- Fuente 2
- Fuente 3
So, continuing, an information retrieval is in charge of the information representation, storage and organization, so that it could be accesed by a user.
For this proposed information retrieval, it has done the following steps:
- Get a Image Set
- Get a Word2Vector model
- Vectorize words
- Choose a Similarity Metric
- Prepare the Image Retrieval
Step 1: Image Set
First to all, to build a Information Retrieval System, in this case, a searcher of images, a resource of images is required. So, there are lots of images with detailed descriptions that were obtained, from diferents sources:
-
30k images with descriptions: To produce the denotation graph, there were created an image caption corpus consisting of 158,915 crowd-sourced captions describing 31,783 images. Reference: Bryan A. Plummer, Liwei Wang, Christopher M. Cervantes, Juan C. Caicedo, Julia Hockenmaier, and Svetlana Lazebnik, Flickr30k Entities: Collecting Region-to-Phrase Correspondences for Richer Image-to-Sentence Models, IJCV, 123(1):74-93, 2017.
-
Pictograms from Arasaac: This website provides a lot a images with short descriptors, used in resources for no verbal communication, thought Alternative and Augmentative Communication Systems.
Step 2: Word Corpus
Oikoitea has been built for spanish speakers, a resource with a lot of words was needed.
- Spanish Billion Word Corpus and Embeddings: This resource consists of an unannotated corpus of the Spanish language of nearly 1.5 billion words, compiled from different corpora and resources from the web; and a set of word vectors (or embeddings), created from this corpus using the word2vec algorithm, provided by the gensim package. These embeddings were evaluated by translating to Spanish word2vec’s word relation test set.
Step 3: Vectorizing words
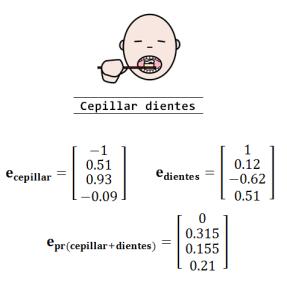
Se puede observar en la Figura 4, inicialmente se han extraído las descripciones y se han expresado en una notación vectorial, obteniendo las palabras del modelo de representación vectorial. Debido a que las descripciones son composiciones de una o más palabras, se ha establecido el promedio de vectores como representación de descripciones en un espacio vectorial, donde se halla el promedio de las palabras de la descripción, y retornando de esta forma un vector resultante de la misma dimensión.
Once the images and the corpus have been gotten,
Step 4: Similarity Metric: cosine distance